煙臺(tái)網(wǎng)站排名優(yōu)化報(bào)價(jià)seo排名優(yōu)化課程
生成模型初認(rèn)識(shí)
參考學(xué)習(xí)資料:李宏毅-機(jī)器學(xué)習(xí)
以下為課程過(guò)程中的簡(jiǎn)易筆記
生成模型
- 為什么要用生成模型?——?jiǎng)?chuàng)造力:同一個(gè)輸入,產(chǎn)生不同的輸出(distribution),有一定概率發(fā)生某種隨機(jī)事件
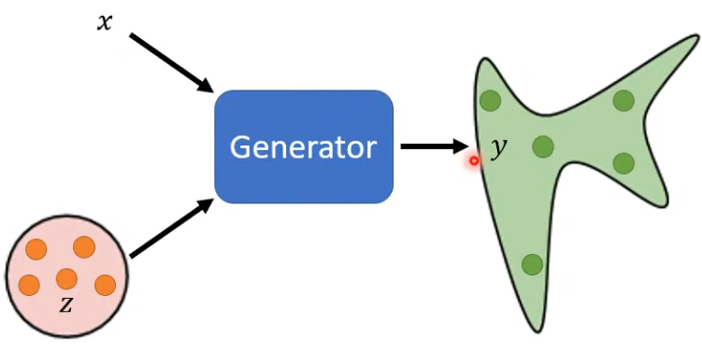
- 輸入:X;從簡(jiǎn)單分布中隨機(jī)sample出的向量z;
- 輸出:distribution
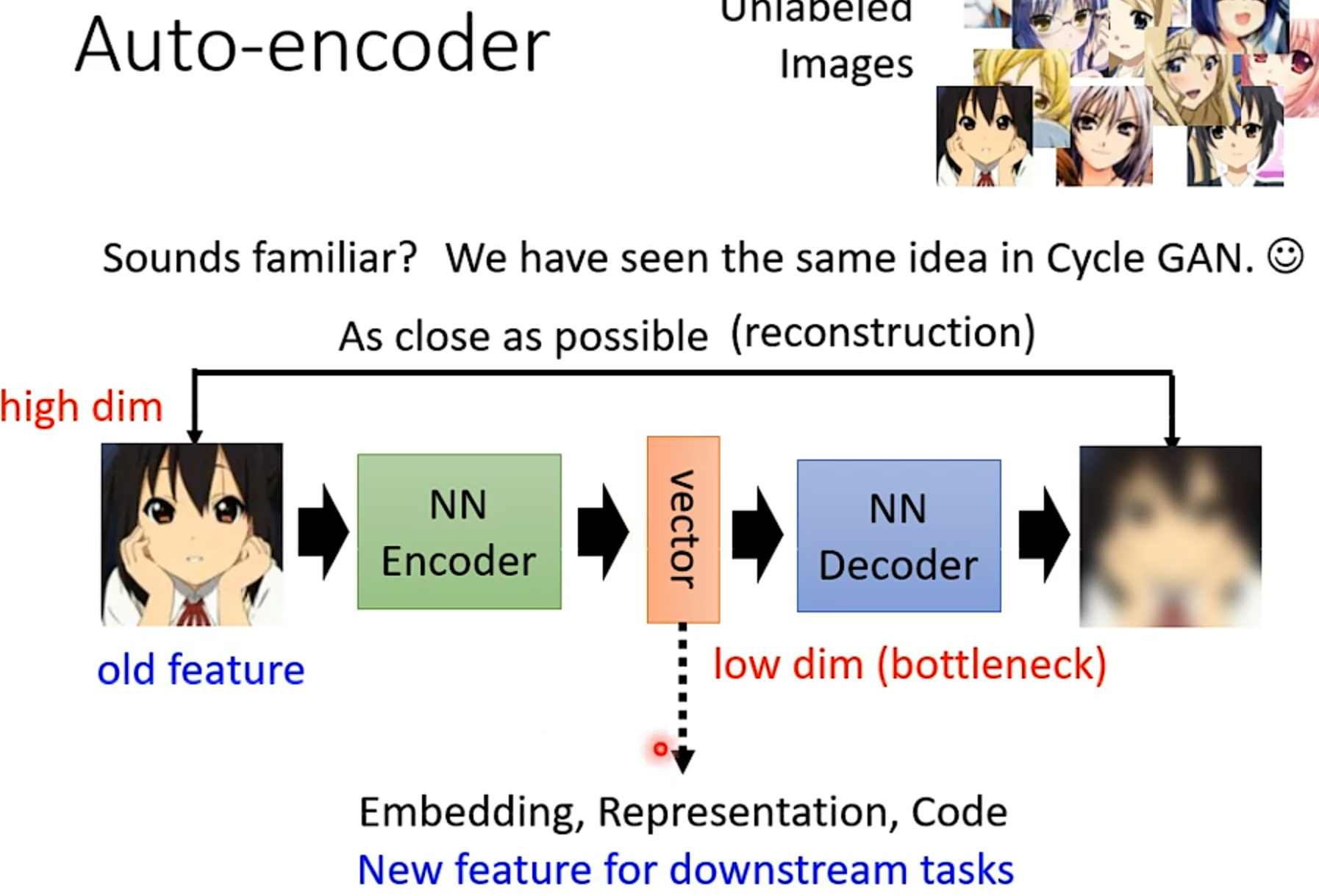
AE
自編碼器
原始輸入特征是有大量冗余的,要重建出原圖不需要那么多特征,只要用low dim的中間特征就可以了
VAE
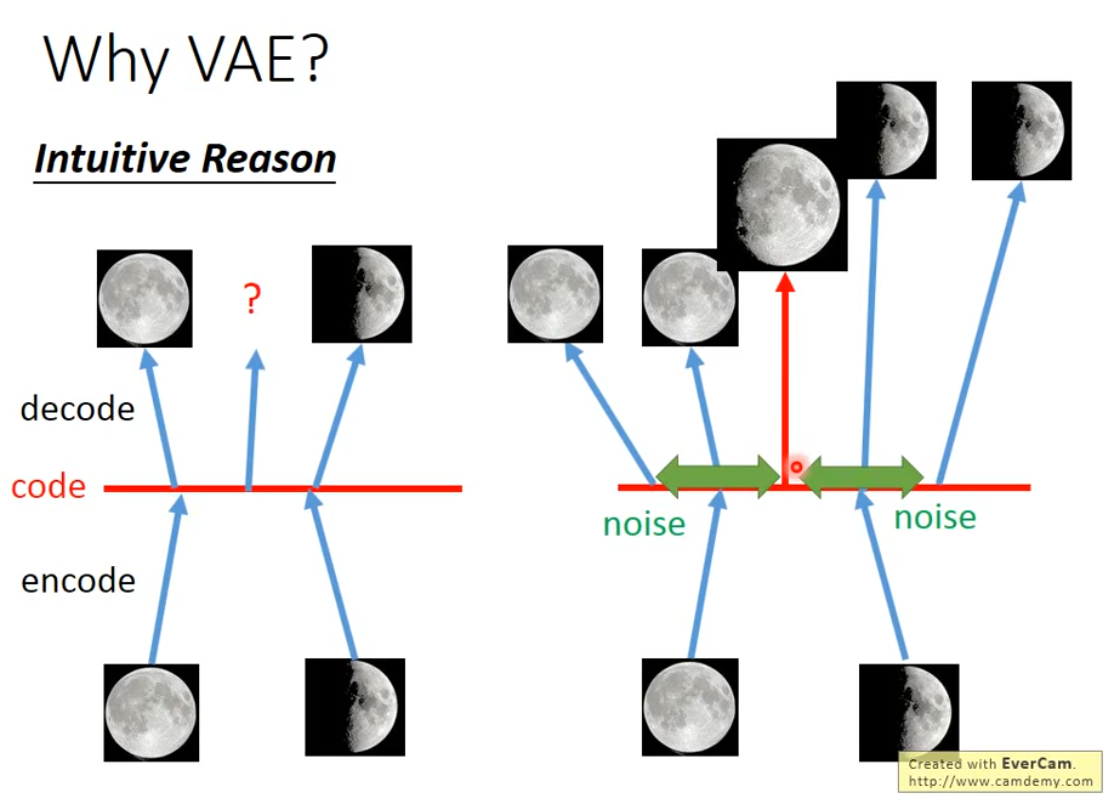
- 在AE的decoder的輸入中增加噪聲,噪聲的方差是 e σ e^\sigma eσ,其中 σ \sigma σ也是由神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)到的
- 因?yàn)樵嫉腁E不存在噪聲,它的預(yù)測(cè)是不可理解的,滿月和弦月的內(nèi)插不一定得到比弦月滿,比滿月弦;但是VAE中加了噪聲后,因?yàn)樵肼暤拇嬖?#xff0c;就要求滿月和弦月之間內(nèi)插的點(diǎn)既和滿月接近,又和弦月接近,因此就會(huì)產(chǎn)生比弦月滿,比滿月弦的結(jié)果
- VAE和GAN不一樣,VAE說(shuō)白了就是要不斷地重建出訓(xùn)練數(shù)據(jù)集中有的樣本,最多是訓(xùn)練集中樣本的組合,是一個(gè)不斷提高模仿力的過(guò)程,要產(chǎn)生和訓(xùn)練集中的樣本相像的圖像,最好能一模一樣,這樣重建錯(cuò)誤就會(huì)最小;但是GAN是要生成以假亂真的圖片,產(chǎn)生的新圖像并不是要和訓(xùn)練集圖片一模一樣,而是要產(chǎn)生圖像的分布和訓(xùn)練集圖像的分布盡可能接近

GAN
Unconditional GAN
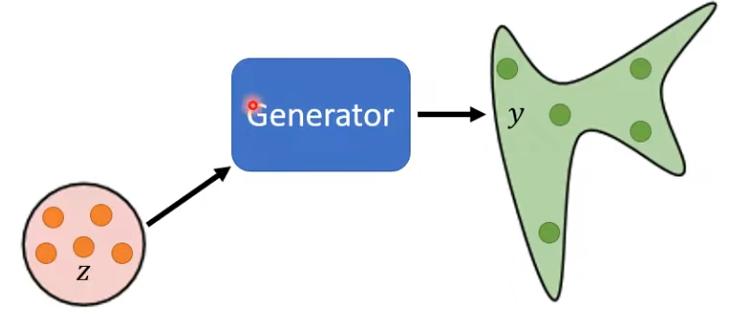
無(wú)條件生成,只輸入從簡(jiǎn)單分布sample的向量z
-
問(wèn):Divergence用于衡量2個(gè)分布的距離,然而 P G P_G PG?和 P D a t a P_{Data} PData?的formulation(公式)都不知道,怎么計(jì)算Divergence?
-
GAN:只要能分別從 P G P_G PG?和 P D a t a P_{Data} PData?兩個(gè)分布中進(jìn)行sample(也就是分別從Generator產(chǎn)生的數(shù)據(jù)和收集到的真實(shí)訓(xùn)練數(shù)據(jù)中做sample),就可以利用Discriminator估算出2者的Divergence
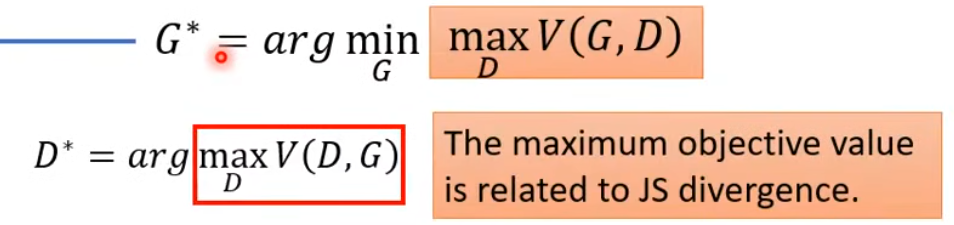
公式理解:
- 要找一個(gè)G,讓紅框里面的值越小越好(代表 P G P_G PG?和 P D a t a P_{Data} PData?兩個(gè)分布的Divergence越小,兩個(gè)分布越像);
- 然而由于兩個(gè)分布的Divergence的公式并不能直接計(jì)算,所以把 P G P_G PG?和 P D a t a P_{Data} PData?兩個(gè)分布的Divergence轉(zhuǎn)化為另一個(gè)優(yōu)化問(wèn)題,通過(guò)引入一個(gè)Discriminator,在Generator給定的情況下,想要找到一個(gè)D,讓V(G,D)越大越好
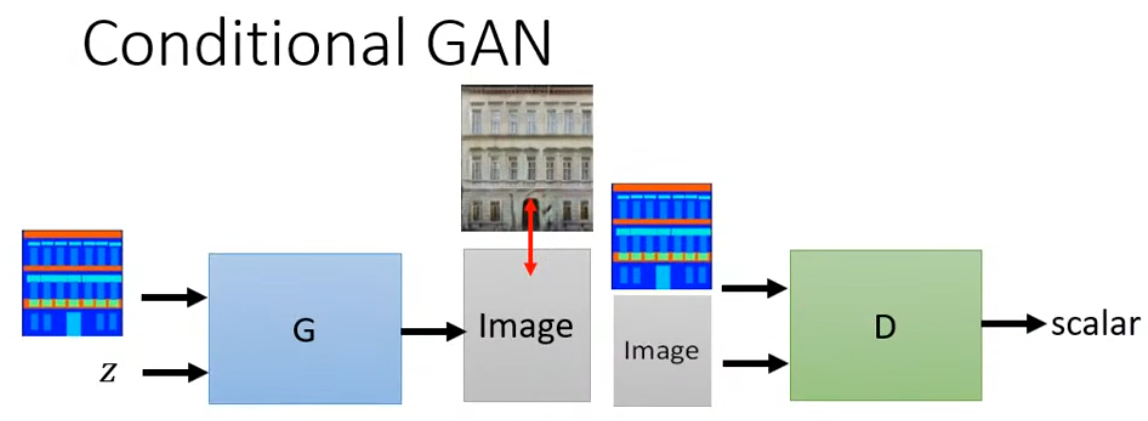
Conditional GAN
有條件生成
Latent Diffusion Model
主要?jiǎng)?chuàng)新:
Difussion Model是在pixel space進(jìn)行加噪和去噪,訓(xùn)練成本高昂,Latent Diffuion Model將加噪和去噪都搬到了latent sapce,訓(xùn)練成本減少,能接受的condition也變多了
組成部分:
- Autoencoder:包括encoder和decoder
- Denoiser:將encoder的輸出加噪后,還原成decoder的輸入
- Conditioning Encoder:可以是任意產(chǎn)生一個(gè)序列tokens的encoder
輸出加噪后,還原成decoder的輸入
3. Conditioning Encoder:可以是任意產(chǎn)生一個(gè)序列tokens的encoder
3個(gè)部分可以分開(kāi)訓(xùn)