百度做網(wǎng)站嗎中國搜索引擎排名2021
根據(jù)提供的數(shù)據(jù)文件【test.log】
數(shù)據(jù)文件格式:姓名,語文成績,數(shù)學(xué)成績,英語成績

完成如下2個(gè)案例:
(1)求每個(gè)學(xué)科的平均成績
(2)將三門課程中任意一門不及格的學(xué)生過濾出來
(1)求每個(gè)學(xué)科的平均成績
- 上傳到hdfs

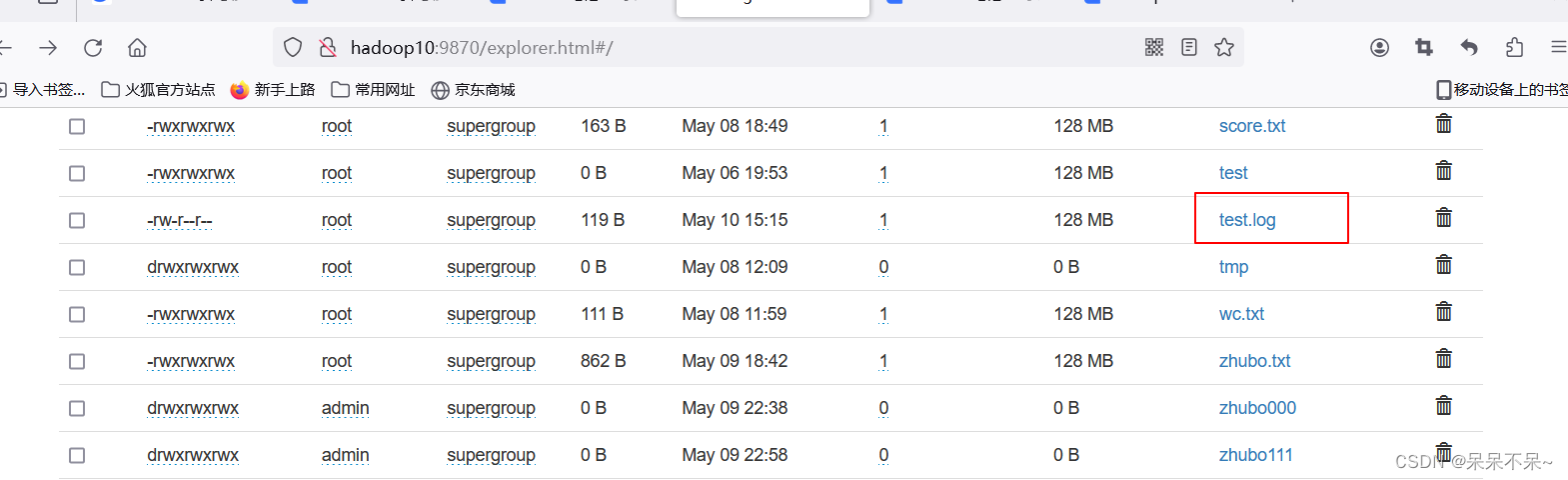
Idea代碼:
package zz;import demo5.Sort1Job;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import java.io.IOException;public class ScoreAverageDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {Configuration conf = new Configuration();conf.set("fs.defaultFS","hdfs://hadoop10:8020");Job job = Job.getInstance(conf);job.setJarByClass(ScoreAverageDriver.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);TextInputFormat.addInputPath(job,new Path("/test.log"));TextOutputFormat.setOutputPath(job,new Path("/test1"));job.setMapperClass(ScoreAverageMapper.class);job.setReducerClass(ScoreAverageReducer.class);//map輸出的鍵與值類型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//reducer輸出的鍵與值類型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);boolean b = job.waitForCompletion(true);System.out.println(b);}static class ScoreAverageMapper extends Mapper<LongWritable, Text, Text, IntWritable> {// 定義一個(gè)Text類型的變量subject,用于存儲(chǔ)科目名稱private Text subject = new Text();// 定義一個(gè)IntWritable類型的變量score,用于存儲(chǔ)分?jǐn)?shù)private IntWritable score = new IntWritable();// 重寫Mapper類的map方法@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {// 將輸入的Text值轉(zhuǎn)換為字符串,并按逗號(hào)分割成數(shù)組String[] fields = value.toString().split(",");// 假設(shè)字段的順序是:姓名,語文成績,數(shù)學(xué)成績,英語成績String name = fields[0]; // 提取姓名int chinese = Integer.parseInt(fields[1]); // 提取語文成績int math = Integer.parseInt(fields[2]); // 提取數(shù)學(xué)成績int english = Integer.parseInt(fields[3]); // 提取英語成績// 為Chinese科目輸出成績subject.set("Chinese"); // 設(shè)置科目為Chinesescore.set(chinese); // 設(shè)置分?jǐn)?shù)為語文成績context.write(subject, score); // 寫入輸出// 為Math科目輸出成績subject.set("Math"); // 設(shè)置科目為Mathscore.set(math); // 設(shè)置分?jǐn)?shù)為數(shù)學(xué)成績context.write(subject, score); // 寫入輸出// 為English科目輸出成績subject.set("English"); // 設(shè)置科目為Englishscore.set(english); // 設(shè)置分?jǐn)?shù)為英語成績context.write(subject, score); // 寫入輸出}}static class ScoreAverageReducer extends Reducer<Text, IntWritable, Text, IntWritable> {// 定義一個(gè)IntWritable類型的變量average,用于存儲(chǔ)平均分?jǐn)?shù)private IntWritable average = new IntWritable();// 重寫Reducer類的reduce方法@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int sum = 0; // 初始化分?jǐn)?shù)總和為0int count = 0; // 初始化科目成績的個(gè)數(shù)為0// 遍歷該科目下的所有分?jǐn)?shù)for (IntWritable val : values) {sum += val.get(); // 累加分?jǐn)?shù)count++; // 計(jì)數(shù)加一}// 如果存在分?jǐn)?shù)(即count大于0)if (count > 0) {// 計(jì)算平均分并設(shè)置到average變量中average.set(sum / count);// 寫入輸出,鍵為科目名稱,值為平均分?jǐn)?shù)context.write(key, average);}}}}
- 結(jié)果:
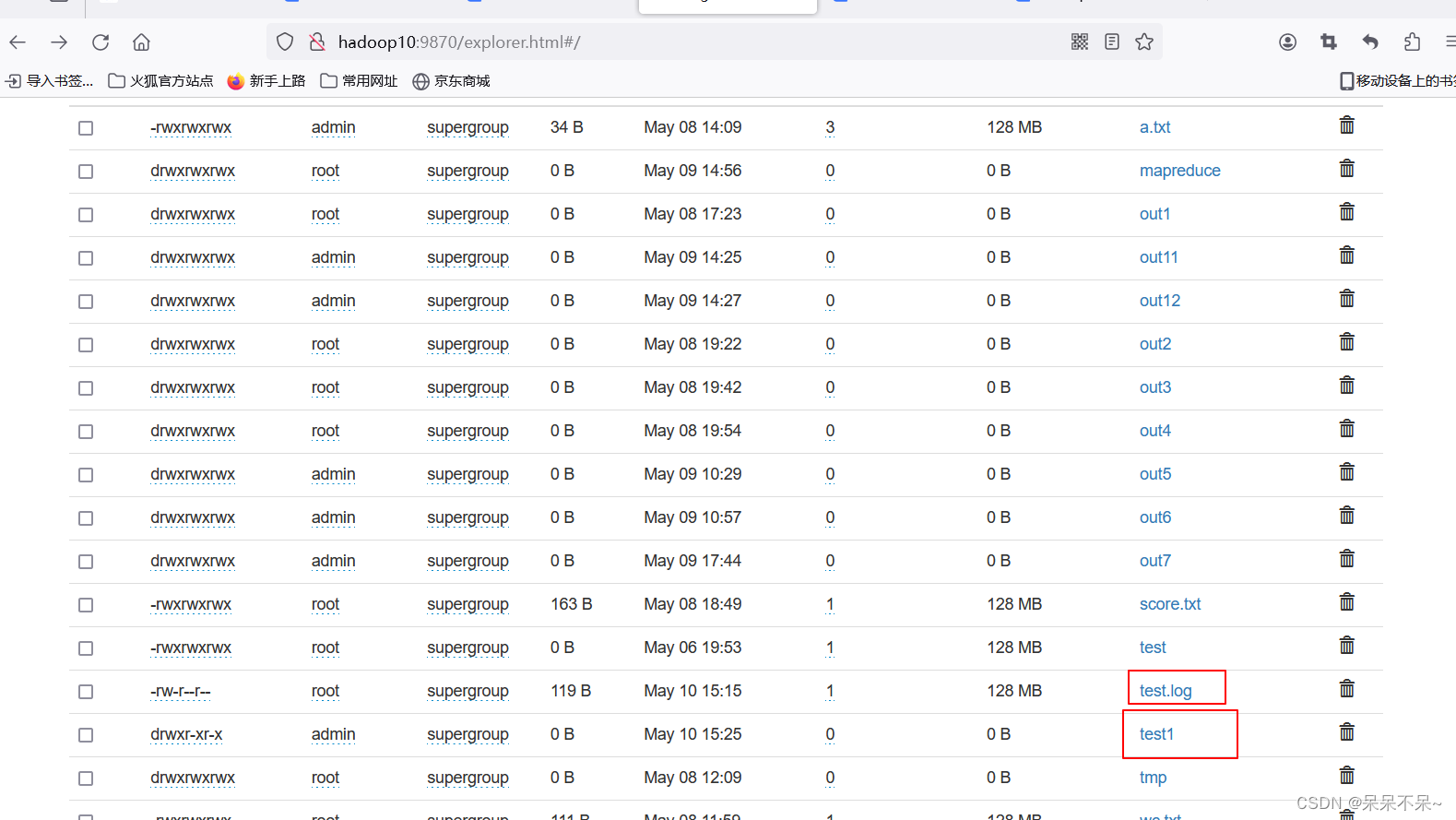
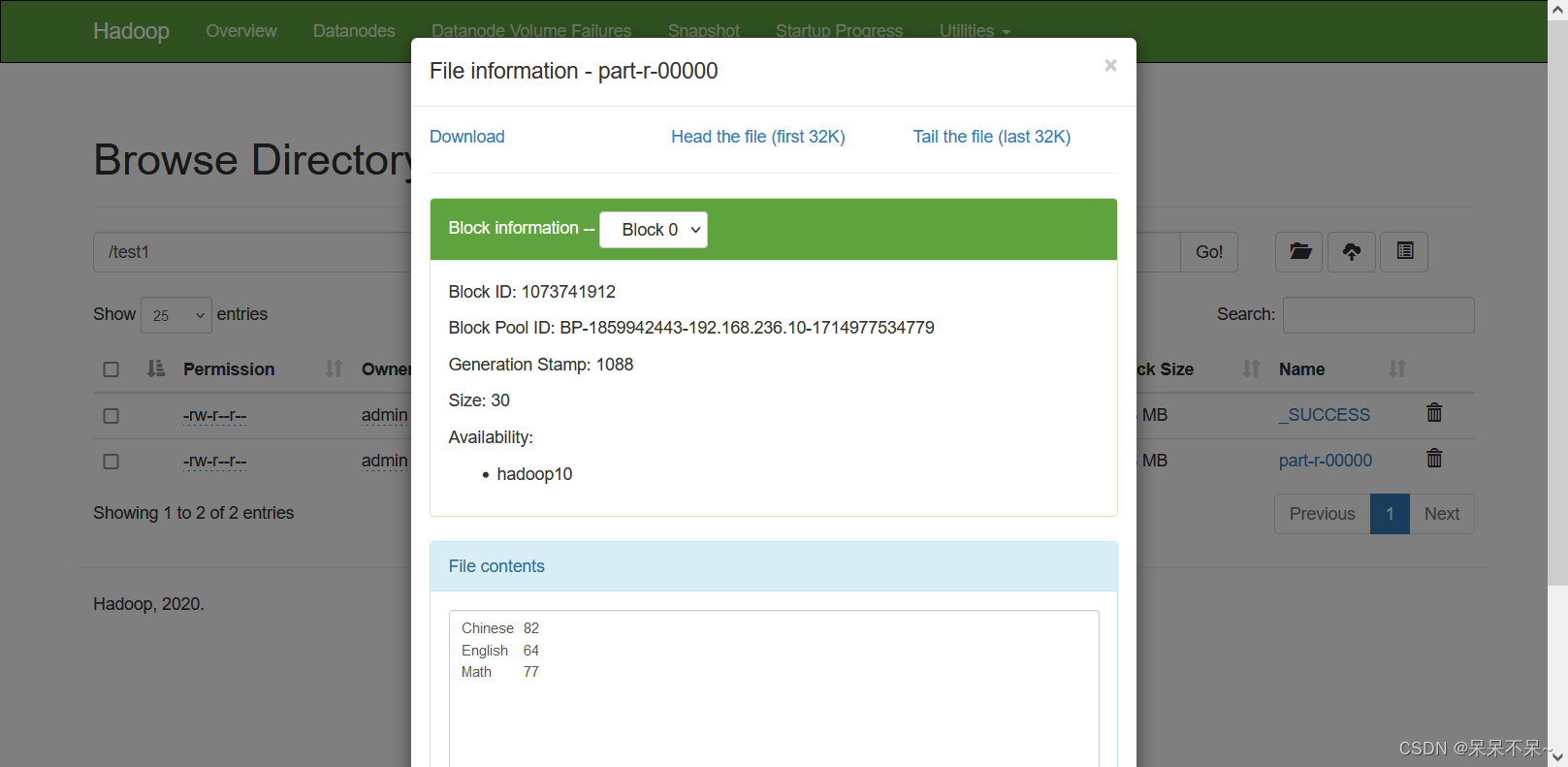 ?
?
(2)將三門課程中任意一門不及格的學(xué)生過濾出來
- ?Idea代碼
package zz;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import java.io.IOException;public class FailingStudentDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {Configuration conf = new Configuration();conf.set("fs.defaultFS","hdfs://hadoop10:8020");Job job = Job.getInstance(conf);job.setJarByClass(FailingStudentDriver .class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);TextInputFormat.addInputPath(job,new Path("/test.log"));TextOutputFormat.setOutputPath(job,new Path("/test2"));job.setMapperClass(FailingStudentMapper.class);//map輸出的鍵與值類型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setNumReduceTasks(0);boolean b = job.waitForCompletion(true);System.out.println(b);}// 定義一個(gè)靜態(tài)類FailingStudentMapper,它繼承了Hadoop的Mapper類
// 該Mapper類處理的是Object類型的鍵和Text類型的值,并輸出Text類型的鍵和NullWritable類型的值static class FailingStudentMapper extends Mapper<Object, Text, Text, NullWritable> {// 定義一個(gè)Text類型的變量studentName,用于存儲(chǔ)不及格的學(xué)生姓名private Text studentName = new Text();// 定義一個(gè)NullWritable類型的變量nullWritable,由于輸出值不需要具體的數(shù)據(jù),所以使用NullWritableprivate NullWritable nullWritable = NullWritable.get();// 重寫Mapper類的map方法,這是處理輸入數(shù)據(jù)的主要方法@Overrideprotected void map(Object key, Text value, Mapper<Object, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {// 將輸入的Text值轉(zhuǎn)換為字符串,并按逗號(hào)分割成數(shù)組// 假設(shè)輸入的Text值是"姓名,語文成績,數(shù)學(xué)成績,英語成績"這樣的格式String[] fields = value.toString().split(",");// 從數(shù)組中取出學(xué)生的姓名String name = fields[0];// 從數(shù)組中取出語文成績,并轉(zhuǎn)換為整數(shù)int chineseScore = Integer.parseInt(fields[1]);// 從數(shù)組中取出數(shù)學(xué)成績,并轉(zhuǎn)換為整數(shù)int mathScore = Integer.parseInt(fields[2]);// 從數(shù)組中取出英語成績,并轉(zhuǎn)換為整數(shù)int englishScore = Integer.parseInt(fields[3]);// 檢查學(xué)生的三門成績中是否有任意一門不及格(即小于60分)// 如果有,則將該學(xué)生的姓名寫入輸出if (chineseScore < 60 || mathScore < 60 || englishScore < 60) {studentName.set(name); // 設(shè)置studentName變量的值為學(xué)生的姓名context.write(studentName, nullWritable); // 使用Mapper的Context對(duì)象將學(xué)生的姓名寫入輸出}}}}- 結(jié)果:
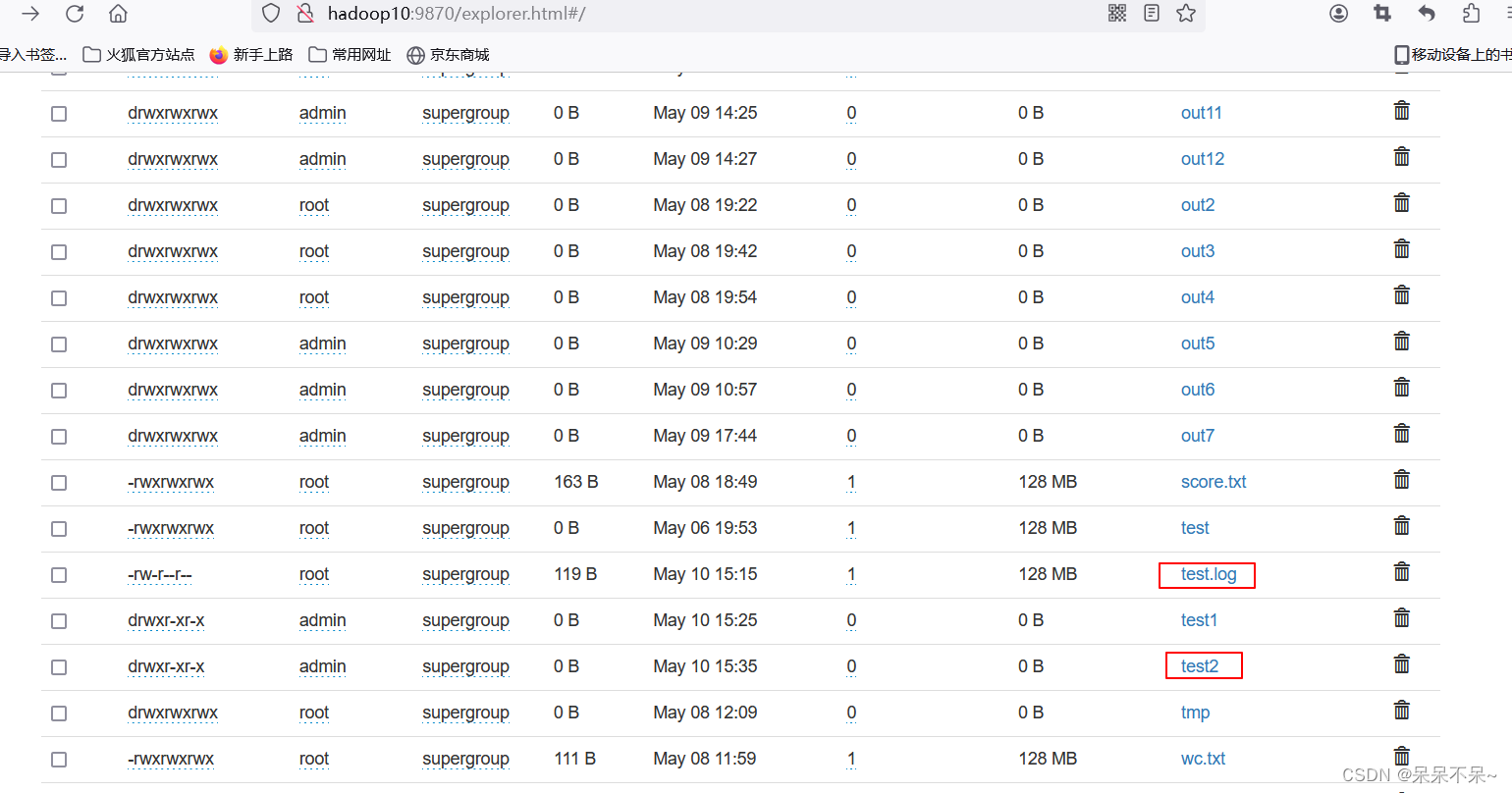
?