網(wǎng)絡(luò)制作軟件seo型網(wǎng)站
1.什么是非監(jiān)督學(xué)習(xí)
常見(jiàn)的神經(jīng)網(wǎng)絡(luò)是一種監(jiān)督學(xué)習(xí),監(jiān)督學(xué)習(xí)的主要特征即為根據(jù)輸入來(lái)對(duì)輸出進(jìn)行預(yù)測(cè),最終會(huì)得到一個(gè)輸出數(shù)值.而非監(jiān)督學(xué)習(xí)的目的不在于輸出,而是在于對(duì)讀入的數(shù)據(jù)進(jìn)行歸類(lèi),選取特征,打標(biāo)簽,通過(guò)對(duì)于數(shù)據(jù)結(jié)構(gòu)的分析來(lái)完成這些操作, 很少有最后的輸出操作.
從訓(xùn)練數(shù)據(jù)的角度來(lái)說(shuō)也是有所區(qū)別:監(jiān)督學(xué)習(xí)的訓(xùn)練數(shù)據(jù)為(x,y), 即同時(shí)具有輸入和輸出數(shù)值,根據(jù)這種輸入和輸出來(lái)判斷訓(xùn)練的結(jié)果是否正確.
但是非監(jiān)督學(xué)習(xí)的數(shù)據(jù)只有輸入數(shù)據(jù)(x),或者說(shuō)非監(jiān)督學(xué)習(xí)就是要處理這些數(shù)據(jù),然后隨著新的數(shù)據(jù)加入再不斷進(jìn)行修改,完成對(duì)數(shù)據(jù)特征提取和區(qū)分的要求.
把相同的數(shù)據(jù)進(jìn)行歸類(lèi),這就是非監(jiān)督學(xué)習(xí)所作的事情.
下面將介紹兩種常用的非監(jiān)督學(xué)習(xí)算法:聚類(lèi)分析和異常檢測(cè)
本文中需要一定的概率論/高中概率的前置知識(shí)
2.聚類(lèi)算法 k-means
(1)什么是聚類(lèi)分析
俺舉個(gè)簡(jiǎn)單點(diǎn)例子,比如說(shuō)我們有兩個(gè)維度的特征值x1 x2,這個(gè)時(shí)候我們根據(jù)特征值把數(shù)據(jù)點(diǎn)描繪在圖片上.

可以很明顯地看到,因?yàn)楦髯缘奶卣鞑煌拖嗨?我們最終可以把原本的數(shù)據(jù)集合分成兩個(gè)集群聚類(lèi)(cluster),我們的目的就是通過(guò)算法找到這兩個(gè)聚類(lèi)究竟有多少成員,有哪些成員
其中一種古老但是經(jīng)典的早期算法K-means可以用來(lái)解決這個(gè)問(wèn)題
(2)K-means算法
在具體解釋這個(gè)算法之前,要說(shuō)明一個(gè)概念:集群質(zhì)心 cluster controids,集群質(zhì)心代表這些集群的一個(gè)中心點(diǎn).
1.Kmeans的算法第一步就是按照人為的需求,隨機(jī)分配多個(gè)集群質(zhì)心
2.然后將每個(gè)點(diǎn)分配給距離自己最近的質(zhì)心,組成一個(gè)集群
3.集群中的點(diǎn)通過(guò)特征值平均,算出一個(gè)中心點(diǎn)位置,然后把這個(gè)集群的質(zhì)心移動(dòng)到這個(gè)位置
4.重復(fù) 2 3 兩個(gè)步驟,直到最后質(zhì)心的距離不發(fā)生改變,即可視為集群操作完成
下面將將會(huì)使用圖片來(lái)進(jìn)行說(shuō)明,我們一共有三十個(gè)數(shù)據(jù)點(diǎn),按照特征值劃分開(kāi)
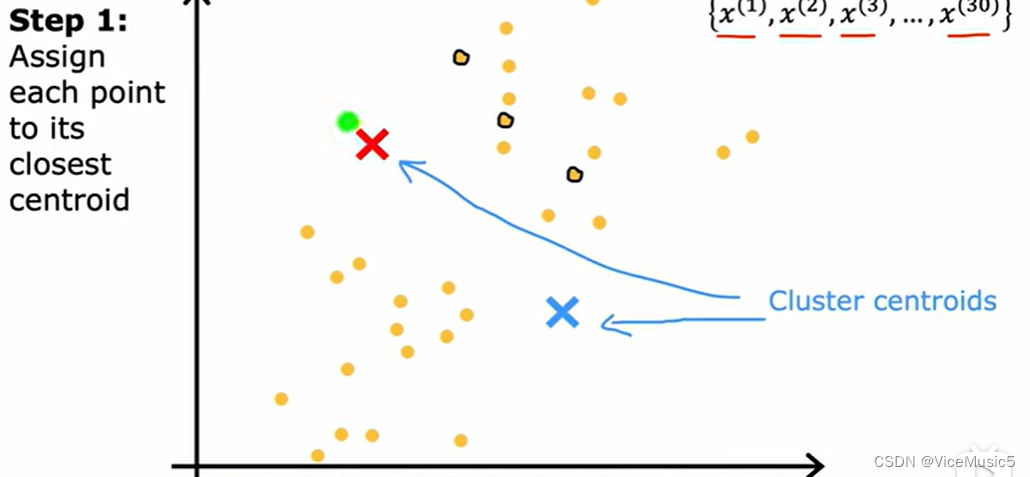
?隨機(jī)分配兩個(gè)質(zhì)心(這里假設(shè)我們需要的是劃分出兩個(gè)集群,然后接下來(lái)是對(duì)每個(gè)數(shù)據(jù)點(diǎn)進(jìn)行歸類(lèi),將其分配給某個(gè)群(嚴(yán)格來(lái)說(shuō)是和距離自己最近的質(zhì)心打上同樣的標(biāo)記)?
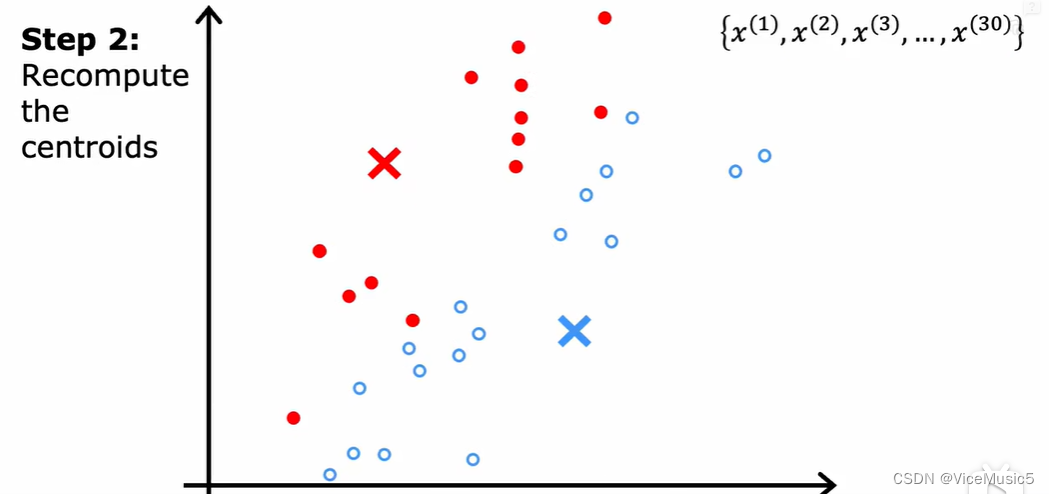
將多個(gè)數(shù)據(jù)點(diǎn)分配到具體的集群以后,這個(gè)時(shí)候暫時(shí)就先不用到集群質(zhì)心cluster controids了
對(duì)于每一個(gè)集群,我們通過(guò)各個(gè)分量之間計(jì)算平均點(diǎn)的方式,計(jì)算出這個(gè)集群的集群質(zhì)心應(yīng)該在什么位置上
然后將集群質(zhì)心移動(dòng)到對(duì)應(yīng)的點(diǎn)上
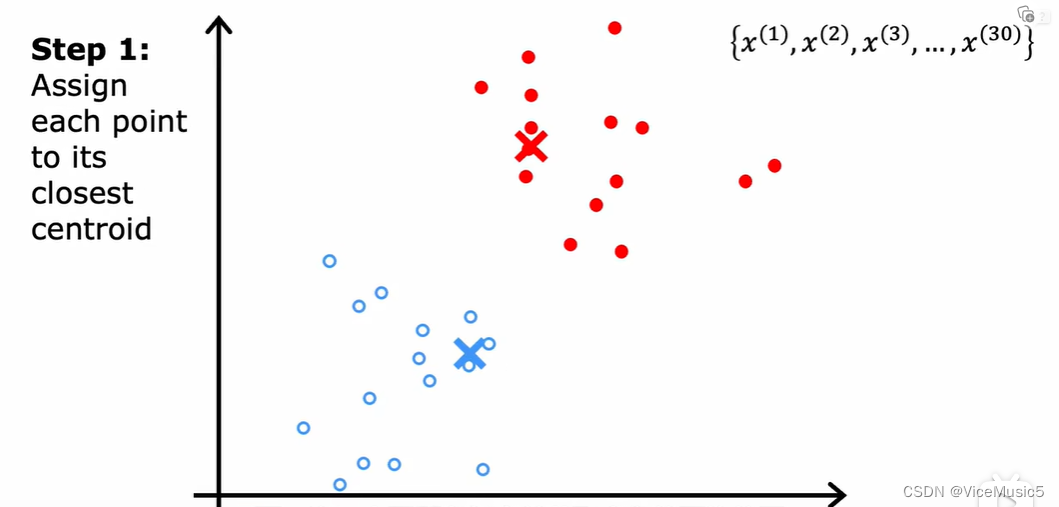
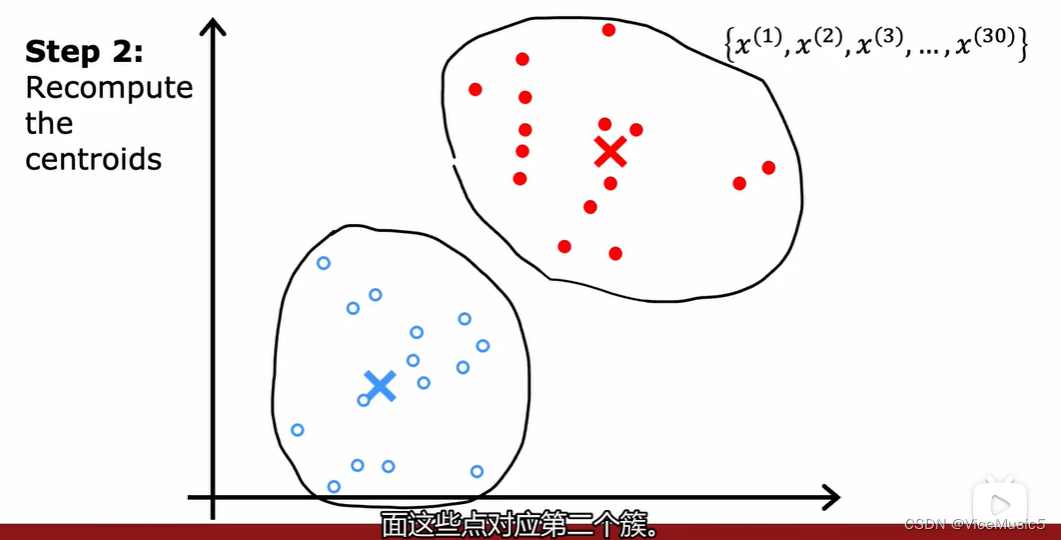
?重復(fù)以上兩個(gè)步驟,最終實(shí)現(xiàn)集群質(zhì)心的固定,到這種程度就可以認(rèn)為規(guī)定數(shù)目的集群已經(jīng)按照要求劃分完成
?(3)聚類(lèi)算法的優(yōu)化
忘記說(shuō)明一點(diǎn),kmeans算法的初始化,隨機(jī)分配集群質(zhì)心,一般是直接在已有的數(shù)據(jù)點(diǎn)中生成,而不是真的憑空捏造一個(gè)(hhhh).但是不同的隨機(jī)選取結(jié)果,最終可能會(huì)導(dǎo)致不同的集群劃分結(jié)果,甚至可能造成unconverge不收斂現(xiàn)象.
類(lèi)似監(jiān)督學(xué)習(xí)中的代價(jià)函數(shù),這里我們同樣是存在代價(jià)函數(shù),只不過(guò)計(jì)算方法有一點(diǎn)點(diǎn)區(qū)別
Kmeans的代價(jià)函數(shù)如下
:代表的是第i個(gè)數(shù)據(jù)點(diǎn)所在的群
:代表的是某個(gè)群的集群質(zhì)心
所以這個(gè)公式的解釋就是:所有點(diǎn)到他們各自所在群的集群質(zhì)心的距離的二范數(shù)(空間距離)的平均值
在比較不同集群算法結(jié)果的時(shí)候,計(jì)算代價(jià)函數(shù)是比較合理的比較方法
而聚類(lèi)算法的優(yōu)化,也是期望代價(jià)函數(shù)能夠降到最低
另外要說(shuō)的是,不合理無(wú)法歸一的情況是客觀存在的,結(jié)局辦法有很多,比如重新進(jìn)行隨機(jī)點(diǎn)的選取,但是kmeans畢竟還是比較早期的算法.可以選用其他算法或者其他改進(jìn)模式,這里就不進(jìn)行贅述了
3.異常檢測(cè)算法 anomal detect
異常檢測(cè)算法通常用于一些特殊的情況,? 比如一些物體的識(shí)別,比如水果,可以按照重量,色澤等等特征來(lái)做區(qū)分,或者珍珠可以按照半徑,色澤等等方式來(lái)判斷一個(gè)珍珠是好是壞.正所謂幸福千篇一律,苦難各有不幸.
我們所遵從的原則是"群體原則",即為服從大多數(shù),大多數(shù)具有相同特征的人被稱(chēng)之為正常.
所以因?yàn)檫@樣,我們要使用高斯分布這一特性
這個(gè)玩意我覺(jué)得大多數(shù)人應(yīng)該在高中或者是大學(xué)的概率論課程中接觸過(guò),在異常檢測(cè)算法之中,我們會(huì)對(duì)每一個(gè)分量進(jìn)行高斯分布計(jì)算
假設(shè)某一批數(shù)據(jù)有很多特征值
??
.............................................................
對(duì)于每一個(gè)分量,例如這個(gè)矩陣的第一列,即每個(gè)樣本的第一個(gè)特征值,對(duì)于這些數(shù)據(jù)我們需要計(jì)算出方差和平均值,然后就能構(gòu)建出一個(gè)分量的高斯式子
然后對(duì)于整體的輸入數(shù)據(jù)來(lái)說(shuō),某個(gè)數(shù)據(jù)xi想要判斷是不是"異常",只需要計(jì)算這個(gè)向量的高斯數(shù)值
? ?(注意一個(gè)很有趣的地方,就算這些特征值可能不是獨(dú)立的,我們這個(gè)式子仍然是成立的)
然后通過(guò)這樣子,判斷該數(shù)據(jù)向量的高斯分布數(shù)值是否大于某個(gè)閥值,即可直到是不是屬于"大多數(shù)"
(2)注意事項(xiàng)
1.在訓(xùn)練的時(shí)候,訓(xùn)練數(shù)據(jù)必須全是正常的數(shù)據(jù),測(cè)試集合中需要包含一些
2.有些特征可能并不是高斯分布,需要我們對(duì)數(shù)據(jù)進(jìn)行適當(dāng)?shù)姆剿幚?/p>
3.不是二維分布不是二維聚類(lèi)!二位聚類(lèi)是根據(jù)兩種不同的特征值劃分出兩種截然不同的集群,兩個(gè)群中的元素則都有各自相同的部分.
而異常檢測(cè)不一樣,異常檢測(cè)做到的是區(qū)分"大多數(shù)"和"異端"